Kafka를 도입한다는 소식을 들었다. 처음 들어본 시스템이자, 데이터 관련 시스템은 처음 접해 보기 때문에 간단한 개념을 정리해 보고자 한다. (cf. 데브원영 - 아차피 카프카 강의 참고 https://www.youtube.com/watch?v=waw0XXNX-uQ)

1. 카프카란?
카프카 홈페이지에 나와 있는 설명으로는, 고성능 데이터 파이프, 스트리밍 분석, 데이터 통합 및 미션 클리티컬 애플리케이션을 위한 오픈 소스 분산 이벤트 스트리밍 플랫폼이라고 한다. 간단히 말해서 데이터 파이프라인을 구축할 때 사용되는 시스템이다.

데이터를 전송하는 주체를 Source Application, 데이터를 전송받는 주체는 Target Application이라 할 때, 각 SA와 TA는 단방향으로 데이터를 전송한다. 하지만 각 SA와 TA는 1대 1 관계가 아닌 N대 M이라는 관계를 가지기도 한다. 이렇게 복잡한 관계가 된다면, 데이터 전송라인 즉 많은 수의 데이터 파이프라인이 존재하게 된다. 데이터 파이프라인이 많아지게 되면, 배포와 장애 대응에 어려워지고 유지보수가 어려워지게 된다는 단점이 있다. 이러한 복잡한 상황을 카프카가 해결해 주고 있다.
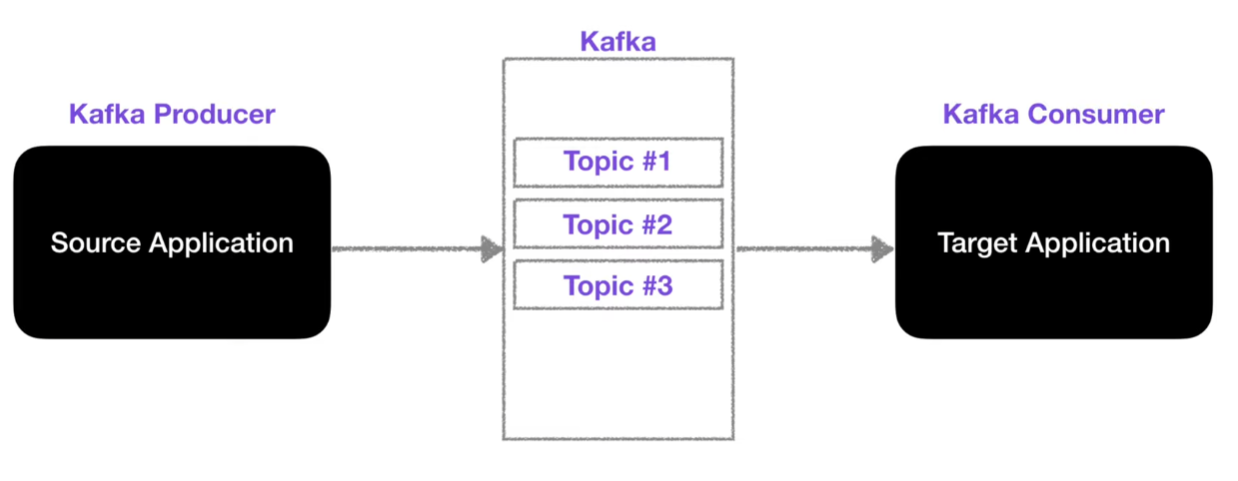
Kafka Producer : 데이터를 넣는 역할, 토픽을 지정하여 데이터를 전송 함
Kafka Consumer : 데이터를 가져가는 역할
카프카는 SA와 TA 사이에서 Q역할을 통해 데이터를 처리한다. 카프카를 사용함으로써 서버이슈나 렉 다운으로부터 데이터 손실 없이 복구가 가능하고, 낮은 지연(latency)과 높은 처리량을 통해 다량의 데이터 처리가 가능하다.
2. Kafka Topic
토픽은 데이터를 구분하는 단위로, 토픽 목적에 따라 이름을 가진다 ( ex. click_log , send_SMS, location_log )
토픽은 여러 개의 파티션(patiton) 단위로 나눌 수 있다. 파티션의 개수는 늘리 수는 있나 줄이는 것은 불가능하다. 파티션을 늘린다면 컨슈머의 개수를 늘려서 데이터 처리를 분산시킬 수 있다. 그렇다면 어떻게 데이터를 적재하고 전송할 수 있을까?
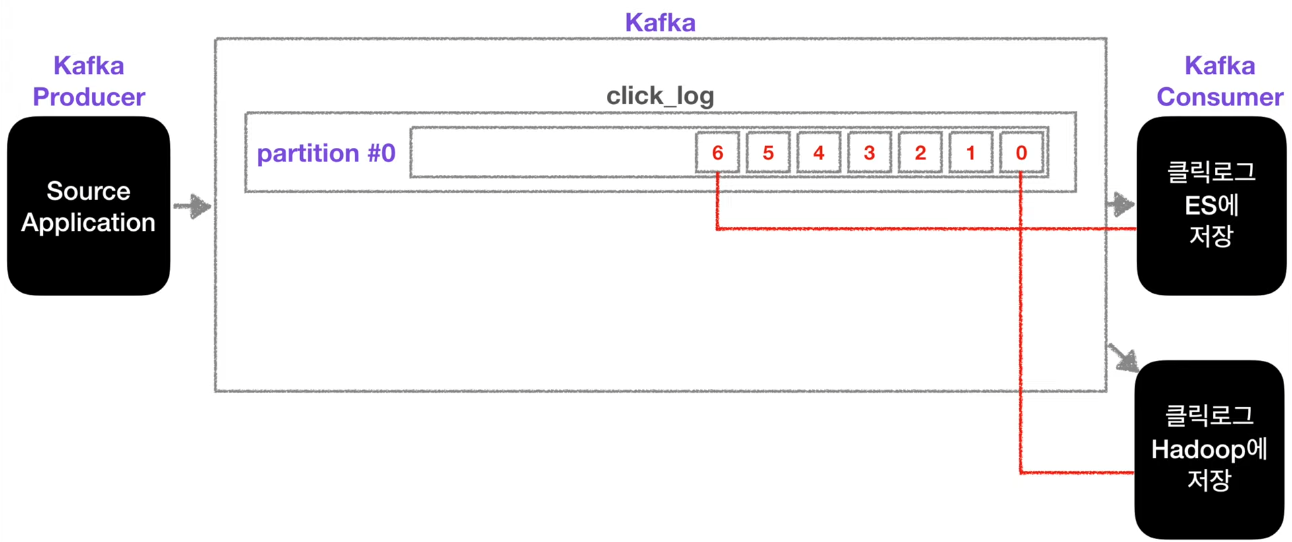
하나의 파티션은 외부의 데이터가 큐와 같이 파티션 끝에서부터 쌓이게 된다. 해당 토픽에 카프카 컨슈머가 붙게 되면 컨슈머는 오래된 순서대로 데이터를 가져간다. 하지만 이때 컨슈머가 데이터를 가져간다 해도 데이터는 삭제되지 않는다.
파티션 0에 저장되어 있는 데이터들은 또 하나의 카프카 컨슈머가 붙게 되면 그때 붙은 컨슈머가 다시 오래된 순서대로 데이터를 가져간다.
이 방식은 카푸카를 사용하는 가장 중요한 이유이기도 한다. 클릭로그를 분석하고 시각화하기 위해 엘라스틱서치에 저장하고 클릭로그를 백업하기 위해 하둡에 저장할 수도 있다.
앞서 말했다시피 파티션은 개수를 늘릴 수 있다. 파티션이 늘어나면 데이터를 어떻게 저장하게 될까? 이때 프로듀서에서는 데이터에 키를 지정할 수 있다. 해당 키를 사용하여 어떤 파티션에 데이터를 할당할 것인지 정할 수 있는 것이다.
- 키가 NULL이고, 기본 파티셔너를 사용할 경우 : 라운드 로빈으로 할당
- 키가 있고, 기본 피티셔너를 사용할 경우 : 키의 해시 값을 구하고, 특정 파티션에 할당
그렇다면 파티션의 데이터는 언제 삭제가 될까?
삭제되는 타이밍은 옵션설정에 따라 다르다. 최대 데이터 보존기간, 최대 데이터 보존 크기를 설정함에 따라 데이터가 언제 삭제되는지 정할 수 있다.
3. Borker, Relication, ISR 핵심요소 3가지

- Broker : 카프카가 설치되어 있는 서버 단위 (3개 이상을 권장)
- Relication : 파티션의 복제를 뜻함
- Relication 1 : 원본 파티션 1개
- Relication 2 : 원본 파티션 1개, 복제 파티션 1개
- Relication 3 : 원본 파티션 1개, 복제 파티션 2개
- 원본 파티션을 Leader파티션, 복제 파티션을 Follower파티션이라고 칭함
- ISR(In Sync Rlica) : 원본 파티션과 복제 파티션을 합쳐서 부르는 말
카프카의 특징 중 "고 가용성"때문에 Relication을 사용한다.

프로듀서가 토픽의 파티션에 데이터를 전달할 때, 전달받는 주체는 Leader파티션이다. 이때 프로듀서에는 ack를 상세옵션이 있다.
- ack0 : 프로듀서는 Leader파티션에 데이터를 전송하고 데이터가 정상적으로 전송되었는지 응답값을 받지 않고 나머지 파티션에 정상적으로 복제가 되었는지 알 수 없다.
- ack1 : Leader파티션에 데이터를 전송하고 데이터를 정상적으로 전달받았는지에 대한 응답값을 받는다. 하지만 나머지 파티션에 정상적으로 복제가 되었는지는 알 수 없다.
- ack all : Leader파티션에 데이터를 전송하고 데이터를 정상적으로 전달받았는지에 대한 응답값도 받고, 나머지 파티션에 정상적으로 복제가 잘 이루어졌는지에 대한 응답값도 받는다.
만약 고 가용성을 위해 Relication을 늘린다고 해도 늘어난 만큼 브로커의 리소스 사용량도 늘어나기 때문에 카프카에 들어오는 데이터와 저장시간을 잘 생각하여 Relication 개수를 정해야 한다.
'[개발] 프로그래밍 > etc.' 카테고리의 다른 글
| EAI (Enterprise Application Integration) (0) | 2023.08.28 |
|---|---|
| CDC (change data capture) 란? (0) | 2023.07.30 |
| 네이비즘 티켓팅 실패이유? (0) | 2023.06.25 |
| 헥사고날 아키텍처 (Hexagonal Architecture) (0) | 2023.03.05 |
| APIM 이란 (0) | 2023.01.29 |


댓글